[paper review] Semantic image segmentation with deep convolutional nets and fully connected crfs
#Vision #Segmentation #DeepLab V1
Abstract
심층 컨볼루션 신경망(DCNN)의 방법과 픽셀 레벨 분류 작업(=시멘틱 영상 분할)을 해결하기 위한 확률적 그래픽 모델을 결합함
DCNN을 높은 수준의 작업에 적합하게 만드는 매우 불변적인 특성 때문에 객체 분할이 잘 안됨
최종 DCNN 계층을 랜던 필드(CRF)와 결함함으로써 해결함
“DeepLab”은 정확도도 높으면서 세그먼트 경계를 나눌 수 있음
세심한 네트워크 재목적 및 웨이블릿 커뮤니티의 '홀' 알고리즘의 새로운 응용을 통해 최신 GPU에서 초당 8 프레임으로 신경망 응답의 고밀도 계산이 가능
1 Introduction
물체감지, 세밀한 분류 등에서 DCNN은 end-to-end 방식으로 훈련되어 좋은 성능을 보임 (세심하게 설계 표현된 SIFT나 HOG 보다)
-> WHY?
로컬 이미지 변환에 대한 DCNN의 내장 불변성 : 부분적으로 데이터의 계층적 추상화를 학습하는 능력을 뒷받침함
이 불변성은 높은 수준의 비전 작업에선 좋은 성능을 보이지만, 포즈 추정, 의미 분할과 같은 낮은 수준의 작업에선 방해가 됨
[이미지 레이블링 작업에 DCNN을 적용하는 데 기술적 장애물]
1. Signal downsampling
: striding의 반복으로 신호 분해능 감소
SO undecimated discrete wavelet transform을 효율적으로 계산하기 위해 hole이 있는 '아트로피' 알고리즘을 사용함
-> DCNN의 효율적인 밀도 계산이 가능
2. spatial 'insensitivity' (invariance)
: 분류기에서 객체 중심 결정을 얻기 위해서는 공간 변환에 대한 불변성이 필요하며, 이는 본질적으로 DCNN 모델의 공간 정확도를 제한함
SO 조건 랜덤 필드(CRF)를 사용해서 모델의 미세한 세부 정보를 캡처하는 능력을 강화함
(CRF는 다양한 분류기에 의해 계산되는 클래스 점수를 픽셀과 에지의 로컬 상호작용에 의해 캡처된 낮은 수준의 정보와 결합하기 위해 의미 분할에 광범위하게 사용되어 왔음)
부스팅 기반 픽셀 레벨 분류기의 성능을 크게 향상시키기 위해 나온 모델
[DeepLab의 장점]
1. 속도 : '아트로피'알고리즘 덕분에 7 DCNN은 8fps로 작동하는 반면, 완전히 연결된 CRF는 0.5초 걸림
2. 정확도 : 좋은 정확성 얻음
3. 단순성 : DCNN과 CRF로 구성
2 Related Work
DCNN으로 semantic segmentation 하는 것은 two-stage 접근법과 대조적임
non-DCNN 전구체는 두번째 순서 풀링 방법
DCNN은 분할 중에 직접 결과를 사용하려고 시도하는 것이 타당함
분할이 조기 결정에 대한 의지를 피하면서 이후 단계에서만 사용되는 것이 유리함
최근에는 분할 없는 DCNN으로 마지막 완전히 연결된 레이어를 컨볼루션 레이어로 대체함
중간 기능 맵의 점수를 샘플링하고 연결하며 거친 결과를 다른 DCNN에 전파한 뒤 미세한 것으로 세분화함
모든 픽셀을 CRF 노드로 취급하고 장거리 종속성을 활용하고 CRF 추론을 사용하여 DCNN 기반 비용 함수를 직접 최적화함
3 Convolutional Neural Networks for dense Image Labeling
VGG-16의 Imagenet을 semantic image segmentation한 방법
3.1 EFFICIENT DENSE SLIDING WINDOW FEATURE EXTRACTION WITH THE HOLE ALGORITHM
1. VGG-16의 완전히 연결된 계층을 컨볼루션 계층으로 변환
But 32픽셀의 stride로는 detection score가 충분하지 않음. 8픽셀의 stride로 더 조밀하게 계산하기 위해 ->
네트워크 마지막 두 최대 풀링 계층 이후 하위 샘플링은 건너뛰고 0을 도입하여 그 길이를 증가시킴 (마지막 세 개의 컨볼루션 계층에서 2배, 처음 완전히 연결된 계층에서 4배)
필터를 그대로 유지하고 2픽셀 또는 4픽셀의 입력 보폭을 사용

'Hole Algorithm'(='Atrous Convolution') : Maxpool Layer 뒤에 따라오는 8-pixel Strided Convolution을 사용하는 대신에 Sparse하게 Convolution을 수행할 수 있도록 중간에 Hole을 채워넣어 줌
im2col 함수(다채널 피처 맵을 벡터화된 패치로 변환)에 추가하여 구현함
일반적으로 적용 가능하고 근사치를 도입하지 않고도 임의의 목표 하위 샘플링 속도로 조밀한 cnn 기능 맵을 효율적으로 계산 가능
[가중치 조정]
VGG-16 마지막 계층에 있는 1000-way Imagenet 분류기를 21-way로 교체함
손실 함수는 CNN 출력 맵의 각 공간 위치에 대한 교차 엔트로피 항의 합계
8로 하위 샘플링됨
모든 위치와 라벨은 전체 손실 함수에 동일한 가중치를 부여함
클래스 점수 맵은 매끄러우며 이를 통해 간단한 이선형 보간을 사용하여 계산 비용으로 분해능을 높일 수 있음
3.2 CONTROLLING THE RECEPTIVE FIELD SIZE AND ACCELERATING DENSE COMPUTATION WITH CONVOLUTIONAL NETS
Dense score 계산을 위해 중요한 것 : 네트워크의 수용적 필드 크기를 명시적으로 제어하는 것!
사전 훈련된 네트워크에 의존하면 일반적으로 수용 필드 크기가 큼
VGG-16 : 224X224(제로 패딩 포함)
컨볼루션 적용될 경우 : 404X404
완전한 컨볼루션 계층으로 변환 후, 첫 번째 완전히 연결된 계층은 큰 7X7 공간 크기의 4096개 필터를 가지며 계산 병목 현상이 됨
--> 해결방법 :
첫번째 FC 레이어를 공간적으로 하위 샘플링(단순 소멸)
SO 네트워크 수용 필드가 128X128(제로 패딩 포함) or 308X308(컨볼루션 적용)로 줄었음,
첫 번째 FC 레이어 연산 시간을 2~3배 단축,
계산 시간과 메모리 공간 줄임
4 Detailed Boundary Recovery : Fully-Connected Conditional Random Fields And Multi-scale Prediction
4.1 DEEP CONVOLUTIONAL NETWORKS AND THE LOCALIZATION CHALLENGE
DCNN score map은 객체의 존재와 대략적인 위치를 예측할 수 있지만 정확한 윤곽을 핀포인트 하기에는 적합하지 않음
[localization 문제를 해결하기 위한 방법]
1. 컨볼루션 네트워크의 여러 계층의 정보를 활용
2. 초픽셀 표현을 사용 / 지역화 작업을 낮은 수준의 분할 방법으로 위임함
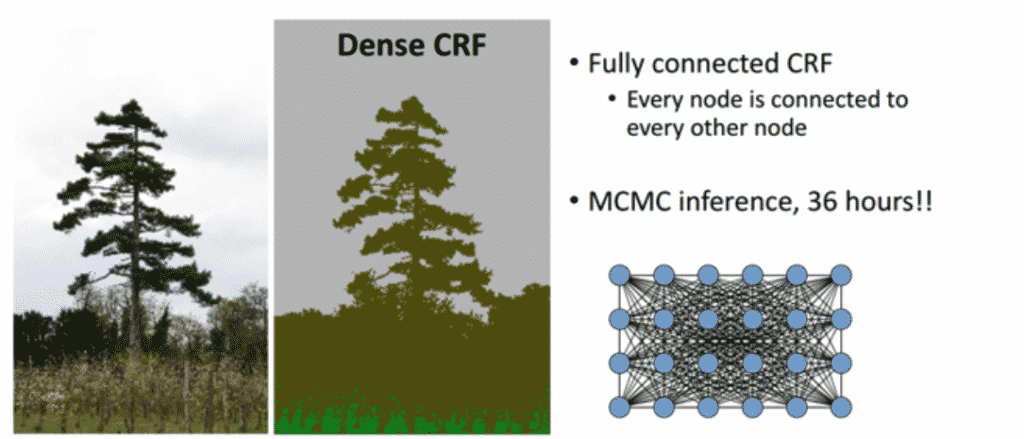
4.2 FULLY-CONNECTED CONDITIONAL RANDOM FIELDS FOR ACCURATE LOCALIZATION

마지막 DCNN 계층의 출력은 평균 필드 추론에 대한 입력으로 사용됨
CRF는 노이즈가 있는 분할 맵을 매끄럽게 하기 위해 보통 사용됨
일반적으로 인접 노드를 연결하는 에너지 항이 포함되어있어 공간 근위 픽셀에 동일한 레이블 할당을 선호
질적으로 단거리 CRF의 주요 기능은 로컬 수공학적 특징 위에 구축된 약한 분류기의 잘못된 예측을 정리하는 것
DCNN 아키텍퍼는 질적으로 다른 레이블 예측을 생성함

score map은 일반적으로 매끄럽고 균질 분류 결과를 산출
SO 단거리 CRF 쓰는 게 안 좋음 (더 부드럽게 하기 때문에 Segmentation이 뭉뚱그려짐)
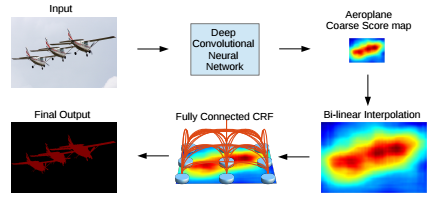
대비에 민감한 potential을 사용함
-> 심층 컨볼루션 신경망(완전 컨볼루션 레이어 포함)의 거친 점수 맵은 bi-linear interpolation(이중 선형 보간법)으로 업샘플링 되고, fully connected CRF가 적용되어 분할 결과를 세분화함
단거리 CRF의 한계 : 얇은 구조를 놓치고 있으며 일반적으로 비용이 많이 드는 이산 최적화 문제를 해결해야 함
--> 해결 방안 : 완전히 연결된 CRF 모델을 시스템에 통함
4.3 MULTI-SCALE PREDICTION
다중 스케일 예측 방법 : 피처 맵이 주 네트워크의 마지막 레이어 피처 맵에 연결된 2계층 MLP(첫 번째 레이어 : 128 3X3컨볼루션 필터, 두 번째 레이어 : 128 1X1 컨볼루션 필터)의 입력 이미지와 각 4개의 최대 풀링 레이어의 출력에 첨부함
소프트맥스 계층에 공급되는 총 기능 맵은 5*128 = 640 채널로 강화됨
학습된 값으로 다른 네트워크 매개 변수를 유지하면서 새로 추가된 가중치만 조정함
효과가 드라마틱하지는 않음


(a) : 'val' set의 성능 / 다중 스케일 기능과 대규모 시야를 모두 활용하여 최상의 성능
(b) : 'test' set의 성능
5 Experimental Evaluation
Dataset
PASCAL VOC 2012 segmentation benchmark
training 1464 , validaion 1449 , testing 1456
10582개의 훈련 이미지가 생성되었음
Training
DCNN 및 CRF training 단계를 분리하여 가장 간단한 형태로 훈련함
DCNN은 VGG-16 사용 : 교차 엔트로피 손실 함수에 대한 확률적 경사 강하를 통해 미세 조정함
매 2000회 반복할 때마다 0.1씩 등급을 매김
0.9의 momentum과 0.00005의 weight decay
완전 연결된 CRF 모델의 매개변수를 교차 검증함
기본값인 W2=3, σγ = 3을 사용하여 최저 값을 찾아냄
매개변수의 초기 검색 범위 : w1 ∈ [5, 10], σα ∈ [50 : 10 : 100] and σβ ∈ [3 : 1 : 10]
평균 필드 반복 횟수를 10으로 수정
Evaluation on Validaion set
DeepLab-CRF 상당한 성능
완전히 연결된 CRF를 사용하면 결과가 크게 향상되어 모델이 복잡한 객체 경계를 정확하게 캡처할 수 있음
Multi-Scale features
Field of view의 효과에 다중 스케일 기능 추가

1. 첫번째 완전히 연결된 계층의 커널 크기
2. 아트로이트 알고리즘에 사용된 입력 보폭 값
DeepLab 모델(=DeepLab-MSC) 1.5% 향상
DeepLab-MSC-CRF 4% 향상
Field of View
'아트리우스 알고리즘'은 우리가 임의로 Field of view를 제어할 수 있게 해 줌
DeepLab-CRF-7X7 : VGG-16 net에서 직접 수정한 것, 커널 크기는 7x7, 입력 보폭은 4
-> 성능은 67.64% but 느림
SO 커널 크기 4x4로 줄임
1. DeepLab-CRF
2. DeepLab-CRF-4X4 : FOV가 크고 성능이 향상됨
3. DeepLab-CRF-LargeFOV : 커널 크기 3X3, 입력 보폭은 12로 사용하고 마지막 두 계층에 대한 필터 크기를 4096에서 1024로 변경함, 값비싼 DeepLab-CRF-7X7 성능과 일치하고 속도가 빨라짐

1열은 DeepLab, 2열은 DeepLab-MSC
다중 스케일 기능을 통합하면 경계 분할이 개선됨
Mean Pixel IOU along Object Boundaries
분할 정확도 평가
'void' 레이블의 트리맵 내에 위치한 픽셀의 평균 IOU를 계산

중간 계층에서 다중 스케일 기능을 활용하고 분할 결과를 완전히 세분화함
연결된 CRF는 개체 경계에 좋은 성능
(a) : 오른쪽 위 : 접지 진실, 왼쪽 아래 : 2픽셀 트리맵, 오른쪽 아래 : 10픽셀 트리맵
Comparison with State-of-art
Reproducibility
bitbucket.org/deeplab/deeplab-public
Test set results
DeepLabMSC-CRF 모델 : 평균 IOU1 l 66.4%, 67.1%
모델의 FOV를 증가시키면 DeepLab-CRF-LargeFOV는 DeepLab-CRF-7X7과 동일한 70.3%의 성능을 내면서 빠름
최고 모델 : DeepLab-MSC-CRF-LargeFOV는 다중 스케일 기능과 대규모 FOV를 모두 사용해서 71.6%의 최고 성능을 달성
6 Discussion
심층 컨볼루션 신경망과 완전히 연결된 조건부 무작위 필드를 결합해서 정확한 예측을 함